Show Facebook Computer Vision Tags to rozszerzenie do przeglądarki Firefox i Chrome, które ujawnia, co Facebook widzi na krążących po nim zdjęciach. Zainstalowałam je pół roku temu i przyzwyczaiłam się już do towarzyszących zdjęciom w prawym górnym rogu tagów. Oprócz rozpoznawania twarzy znajomych, jakie rodzaje informacji czyta Facebook i co potrafi, hm, stwierdzić?
Facebook rozpoznaje postaci ludzkie. Widzi uśmiech oraz autoportret. Potrafi policzyć ludzi na zdjęciu, choć nie zawsze precyzyjnie. Wie, czy zdjęcie zostało zrobione na dworze czy we wnętrzu, i czy to sypialnia, czy pokój stołowy. Że mecz amerykańskiego baseballa to też wie. Wie, że samochód to samochód, okulary to okulary, garnitur to garnitur i że bluzka jest w paski. Widzi napisy. Czy potrafi je przeczytać? Pewnie od dawna zna już angielski, ale czy polski? Wątpię. Moim zdaniem wciąż jeszcze polski język, bezpieczny język.
 Otagowana galeria zdjęć projektu „Wióry lecą”
Otagowana galeria zdjęć projektu „Wióry lecą”
Od kwietnia 2016 roku, gdy wrzucasz na portal zdjęcie, Facebook automatycznie taguje je słownym opisem, założeniem co do ogólnej treści zdjęcia:
<img csrc="https://facebook.com/some-url.jpg"
alt="Image may contain: golf, grass, outdoor and nature"
width="316" height="237">
To właśnie te alt tagi odczytuje oprogramowanie dla osób słabowidzących bądź niewidomych. Programy udźwiękawiające mogą wtedy opowiedzieć zdjęcie, nawet jeśli nie zostało ono otagowane przez samego wrzucającego. Facebook tak robi, ponieważ jego „misją jest sprawić, aby świat był bardziej otwarty i połączony”. Adam Geitgey, twórca rozszerzenia Show Facebook Computer Vision Tags, twierdzi jednak, że warto uświadomić sobie, jak wiele informacji wydobywa dziś portal ze zdjęć.
Facebook widzi, że postać na zdjęciu jest na scenie.

Facebook widzi, że człowiek stoi lub siedzi. I psa, śnieg, ogólnie naturę (może po drzewach rozpoznaje).

Widzi wodę. I łabędzia słusznie jako ptaka rozpoznaje.

Na razie jest to ogląd dość powierzchowny, ma się wrażenie. Facebook jest bowiem póki co, wciąż póki co, kulturowo ograniczony do rytuałów kultury globalnie ustandaryzowanej: jedzenie, siedzenie, komputer, scena, uśmiechanie się, selfie, zachód słońca nad oceanem. I mam rację, kiedy tak myślę. Oto zdjęcie z warszawskiego tramwaju. Mężczyzna z szablą to dla Facebooka jedynie człowiek siedzący.

Także z kurami niezbyt sobie radzi, odczytając je jako buty.

Podwójny portret tej samej osoby zostaje uznany za osoby dwie, osobne.

Jest więc wciąż przestrzeń na błędy. Naiwne byłoby jednak myśleć, że Facebook spocznie na laurach i nie będzie się dalej uczyć. To pomyślawszy, natrafiam na zdjęcie dwójki ludzi w goglach do VR, co do którego rozszerzenie Show Facebook Computer Vision Tags twierdzi, że zdjęcie zostało zrobione na zewnątrz. Czy Facebook wie, co widzą ludzie w goglach? Wie, że są na dworze? Może.

Może Facebook wcale nie jest taki znowu naskórkowy. A konkretnie chodzi o Deep ConvNet, czyli głęboką konwolucyjną sieć neuronową tworzoną przez zespół badawczy Facebooka zajmujący się sztuczną inteligencją (Facebook AI Research – w skrócie FAIR). Brzmi to dość onieśmielająco, więc musiałam z kimś o tym porozmawiać. Zwróciłam się do Pawła Cyrty, który twierdzi, że zna się na uczeniu maszynowym. Cyrta mówi, że:
Głęboka konwolucyjna sieć neuronowa to sieć neuronowa składająca się z wielu warstw filtrów dokonujących operacji konwolucji na danych wejściowych. Sieć taka ma właściwości adaptacji do sygnału wejściowego i uczenia się wykrywania krawędzi na pierwszych warstwach, przez elementy obiektów, aż po całe obiekty w warstwach wyższych.
 Schemat Deep ConvNet z Wikipedii
Schemat Deep ConvNet z Wikipedii
Wciąż czuję się onieśmielona, ale rozumiem to jako kilkuetapowe analizowanie i kategoryzowanie obiektów na obrazie na podstawie ich, no, kształtów i elementów, z których się składają. Sieć analizuje miliony próbek i dlatego ma solidne podstawy do wyciągania wniosków. Jak nasz mózg, który przez wiele lat ogląda, ogląda, ogląda, przypisuje do szufladki, nazywa.
Cyrta podsyła mi też link do szerzej omawiającej temat oszałamiającej prezentacji autorstwa dr hab. Adriana Horzyka z wydziału Elektrotechniki, Automatyki, Informatyki i Inżynierii Biomedycznej w Akademii Górniczo-Hutniczej w Krakowie.

Prezentacja intryguje ponadczasowym stylem z lat 90. i potwierdza moje rozumienie działania omawianej tu pokrótce sieci. Analizowane warstwy to kolejne etapy upraszczania bardziej skomplikowanych cech, aby dojść do końcowej kategorii, np. garnitur.
Cyrta mówi, że ojcem głębokich konwolucyjnych sieci neuronowych jest profesor Yann LeCun. Francuz, który wymyślił je, pracując jeszcze dla AT&T Bell Labs. LeCun zrobił wtedy projekt dla amerykańskiej poczty. Sieć rozpoznawała ręcznie pisane numery i adresy na kopertach.

Od 2013 roku LeCun jest dyrektorem Facebook AI Research i podobnie jak dr Horzyk lubi sznyt lat 90. w swoich prezentacjach. Kolejne slajdy prezentacji „What's Wrong With Deep Learning?” to poszczególne etapy rozwoju sieci. Na stronie 49 zaczyna się opowieść o rozpoznawaniu twarzy.
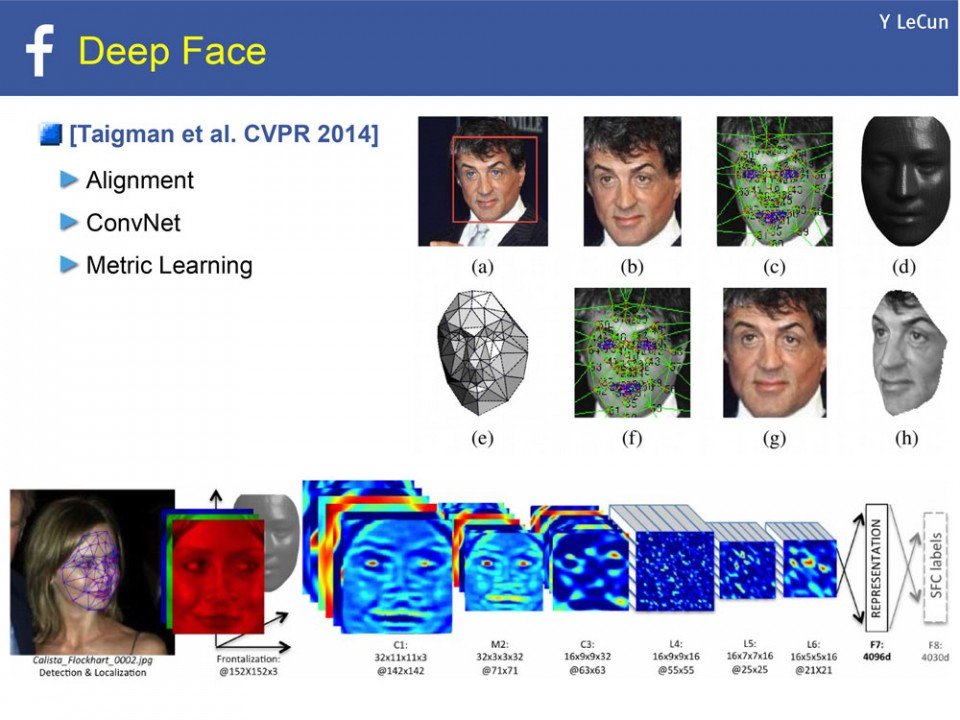
Dziś to dla nas nic nowego czy poruszającego. Tagujemy, lub nie, naszych ludzi na Facebooku, zdaje się to być już funkcją zupełnie naturalną. Przeglądarkowe rozszerzenie Show Facebook Computer Vision Tags też mnie nie szokuje, nie czuję się dużo bardziej odkryta, niż i tak jestem. Natomiast ciekawi mnie przeskok od biernego odczytywania obiektów na zdjęciu do aktywnego wytwarzania nowych obrazów dzięki sztucznej inteligencji, kolejny poziom możliwości głęboko uczącej się sieci.
Efekt może być zabawny, tak jak w projekcie DeepWarp rosyjskich naukowców ze Skolkovo Institute of Science and Technology, który animuje oczy na zdjęciu. Spróbujcie sami tu.
 Paweł Cyrta przerobiony przez DeepWarp
Paweł Cyrta przerobiony przez DeepWarp
Jeśli natomiast posiadamy spore ilości dobrej jakości materiału audiowizualnego, powiedzmy nagrań z wywiadami z Barackiem Obamą, możemy stworzyć na ich podstawie fejkowe wideo. Syntetyczny Obama powstał latem 2017 roku w laboratoriach Uniwersytetu Waszyngtońskiego i nie pomyślałabym, że to fejk, gdyby mi ktoś nie powiedział. Dotrwajcie do pierwszej minuty i pięćdziesiątej trzeciej sekundy poniższego filmu, żeby zobaczyć, jak technologia może też gmerać w czasie: Obama 2017 vs. Obama 1990.
I to już jest mniej zabawne.
Tekst dostępny na licencji Creative Commons BY-NC-ND 3.0 PL (Uznanie autorstwa-Użycie niekomercyjne-Bez utworów zależnych).






































































































![ARS ELECTRONICA 2012: codziennik [5]](/public/media/article/image_thumb/3904.jpg?cb=401)






















