
MACIEJ JAKUBOWIAK: Niedawno opublikowaliśmy w dwutygodnik.com polemikę, jaka wywiązała się po ukazaniu się artykułu Stephena Marche’a „Literatura to nie dane”. W dyskusji pojawiały się obawy, że analiza danych cyfrowych zastąpi tradycyjnie rozumianą humanistykę, skupioną na analizie tekstów i dzieł sztuki.
LEV MANOVICH: Humanistyka cyfrowa jest przecież w gruncie rzeczy bardzo tradycyjna. Jej przedstawiciele nie zmienili obszaru zainteresowań, nie analizują na przykład XIX-wiecznych dzienników, ale wciąż skupiają się na powieściach pisanych przez profesjonalnych pisarzy. Nie sądzę w każdym razie, żeby analiza big data miała zastąpić tradycyjną humanistykę.
Natomiast w ramach analityki kulturowej, którą się zajmuję wraz z zespołem Software Studies Initiative, analizujemy m.in. media społecznościowe i nie musimy ograniczać się do profesjonalistów, możemy zająć się zwykłymi użytkownikami. Powinniśmy zacząć myśleć szerzej, niż tylko o wybitnych twórcach: fotografach, filmowcach, pisarzach. Powiedzmy, że chciałbym się dowiedzieć czegoś o XIX wieku. Mogę oczywiście skoncentrować się na Tołstoju i Flaubercie, ale równie interesujące byłoby sprawdzenie, czym zajmowali się inni piszący, mniej znani. To pozwoliłoby zrozumieć, jak rozwijał się język powieściowy, jakimi tematami się zajmowano, jak się zmieniały. Analityka kulturowa to nie żaden zmyślny pomysł na pozbycie się humanistyki. To raczej sposób patrzenia na kulturę.
I choć pewnie arcydzieła przynoszą więcej satysfakcji, to jeśli chcemy zajmować się kulturą współczesną – zdjęciami na Instagramie, projektowaniem grafiki czy stron internetowych – nie dysponujemy żadnym trwałym kanonem. W kulturze współczesnej nie istnieją kanony. Być może w przyszłości ktoś będzie w stanie stwierdzić, kto był najważniejszym fotografem publikującym na Instagramie. Dzisiaj tego nie wiemy. Podobno 10 procent wszystkich zdjęć stworzonych przez człowieka powstało w ciągu ostatnich 12 miesięcy. Jak można to zbadać?
Lev Manovich był gościem festiwalu NInA WERSJA BETA, który odbył się pod koniec września 2015. Brał udział w panelach dyskusyjnych poświęconych opowiadaniu i bazom danych oraz żywotności archiwum, prezentując przy tej okazji najnowsze projekty zrealizowane przez jego zespół Software Studies Initiative.
Czy analizy big data mogą wpłynąć na nasze przekonania o tym, kto był lub jest ważnym, wpływowym artystą?
Używamy dziś powszechnie takich wskaźników, jak liczba sprzedanych książek czy liczba followersów na Twitterze. W mediach społecznościowych możemy jednak wykroczyć poza takie rankingi i dostrzec istnienie wielu luźnych społeczności, składających się choćby z 200 członków. Na przykład kiedy w ramach projektu „Selfiecity” analizowaliśmy trzy tysiące zdjęć z pięciu miast, badając zjawisko selfie z perspektywy demograficznej, nie pytaliśmy, które z nich są najpopularniejsze. Usiłowaliśmy za to wskazać pewne zbiory spójności, charakteryzujące się podobną treścią, wykorzystaną techniką fotograficzną, stylem.
Na tym polega różnica w stosunku do dawniejszych badań socjologicznych czy antropologicznych, w ramach których zajmowano się tylko jedną wspólnotą naraz. Wykorzystując duże zbiory danych, możemy wskazywać dziesiątki, a nawet setki takich społeczności, z których każda będzie inna. Dzięki temu możemy uzyskać bardziej szczegółowy i złożony obraz społeczeństwa i kultury.
To dlatego big data przyciągają dzisiaj tak wielu badaczy?
Mnóstwo badań na temat mediów społecznościowych – Facebooka, Twittera, Instagrama – powstaje dzisiaj dlatego, że stosunkowo łatwo można pozyskać do nich ogromne ilości danych. Wystarczy skorzystać z API i prostego skryptu, żeby ściągnąć miliony postów.
Lev Manovich
ur. 1960 r. w Moskwie, od 1981 r. w Stanach Zjednoczonych, badacz nowych mediów, profesor w The Graduate Center, City University of New York, założyciel i dyrektor Software Studies Initiative, autor m.in. książek „Język nowych mediów” (2001), „Soft Cinema: Navigating the Database” (2005), „Software Takes Command” (2013). W 2014 r. magazyn „The Verge” zaliczył go do grona „50 najbardziej interesujących ludzi tworzących przyszłość”. Zajmuje się sztuką nowych mediów, badaniem interfejsów komputerowych oraz analizą big data. Twórca metody analityki kulturowej (cultural analytics), polegającej na badaniu dużych zbiorów danych przy pomocy wizualizacji.
Inną kwestią jest wykorzystanie big data do przewidywania przyszłości. Parę lat temu Google uruchomiło słynny projekt Google Flu Trends, w ramach którego za pomocą analizy liczby zapytań wpisywanych w wyszukiwarkę, dotyczących grypy, lekarstw, sposobów leczenia, usiłowano przewidywać tendencje rozwoju grypy. Od tego czasu powstało wiele badań, w których prezentowano możliwości wykorzystania danych z mediów społecznościowych do przewidywania zjawisk społecznych, ekonomicznych czy demograficznych. Jeden z projektów, którymi się obecnie zajmujemy, dotyczy zdjęć selfie publikowanych na Twitterze. Na podstawie analizy częstotliwości występowania pewnego ich rodzaju potrafimy wyznaczyć poziom społecznego zadowolenia z 60-procentową zgodnością w stosunku do wskaźników Instytutu Gallupa.
Ale metody badania kultury sprzed epoki cyfrowej, choć może bardziej czasochłonne, potrafiły być bardziej precyzyjne. Jak w przypadku antropologów, którzy podróżowali w różne miejsca na świecie i spędzali w nich kilka lat, żeby je opisać. Zresztą socjologowie wciąż przeprowadzają badania ankietowe, a jednym z najbardziej imponujących zbiorów danych, jakim dysponujemy, jest spis powszechny. Może i wykonujemy go co 10 lat, ale za to trafiamy dzięki temu do każdego obywatela, zadając mu całe mnóstwo pytań. Najbardziej mnie interesują połączenia między danymi cyfrowymi a rzeczywistością. Powiedzmy, że chciałbym przeanalizować, jak w ostatnich latach zmieniała się Warszawa. Czy mógłbym polegać tylko na danych z mediów społecznościowych?
W ramach Software Studies Initiative analizujecie dane dostarczane przez internetowych gigantów: Twittera, Instagram. Te dane są w pewien sposób sprofilowane i ukształtowane przez rynkowe interesy tych firm. Czy nie obawiacie się, że wasze badania doprowadzą tylko do odtworzenia założeń, które były wpisane w te materiały już od początku?
W pierwszych latach istnienia naszego laboratorium zajmowaliśmy się głównie zbiorami danych dotyczących sztuki: kina, animacji, filmu, plakatu. Interesowały nas profesjonalne obiegi kultury. Przeprowadziliśmy np. analizę miliona stron mangi. Unikaliśmy mediów społecznościowych dokładnie ze względu obawy, o których wspomniałeś.
Jednak po 6–7 latach pracy nad zbiorami muzeów i innych instytucji kultury zdaliśmy sobie sprawę, że jakość tych danych jest bardzo zła. Za każdym razem musieliśmy odrzucać 50 procent z nich. W tym miesiącu Museum of Modern Art ogłosiło, że udostępni na GitHubie połowę swojej, liczącej ponad 200 tys. obiektów, kolekcji. Pokazałem te dane swoim studentom pierwszego roku. Były tam podstawowe informacje: tytuł, nazwisko artysty, miejsce urodzenia i parę innych. Jednak pracownicy MoMA, którzy tworzyli te dane, nie mieli najwyraźniej pojęcia, jak się później z nimi pracuje. Było wiele dziwnych poprawek do pisowni nazwisk czy różne zakresy dat, których nie da się potem zwizualizować. Instytucje kultury nie wiedzą, jak tworzyć zbiory danych. Praca z mediami społecznościowymi jest pod tym względem łatwiejsza, dane są idealne, niczego w nich nie brakuje.
A ukryte założenia? Kiedy zrobiliśmy nasz pierwszy projekt z wykorzystaniem zdjęć z Instagrama, „Photorails”, przeanalizowaliśmy pewne konwencje występujące w tym serwisie. Mój utalentowany współpracownik, Nadav Hochman, pokazał, w jaki sposób sam Instagram stanowi medium w takim sensie, w jakim medium był np. film, warunkujący to, co i jak można pokazać ze względu na uwarunkowania technologiczne. Instagram wymusza kwadratowy format zdjęcia, ale – co już mniej oczywiste – skłania również do publikowania zdjęć, które odnoszą się do aktualnego momentu. Oczywiście, mamy w tym przypadku do czynienia z pewnymi założeniami, z pewną ideologią, ale nie to jest najważniejsze. Najważniejsze jest to, że Instagram, jak każde medium w przeszłości, wytwarza pewne konwencje, które strukturyzują dane. Kiedy spojrzy się na Instagram, można dostrzec funkcjonujący tam szczególny język wizualny. Jasne, jest tam sporo przypadkowych, codziennych zdjęć, ale jest też mnóstwo takich, które wpisują się w określone kategorie: modne buty, zdjęcia od pasa w górę, zdjęcia tego, co jest na stole.
Ostatecznie to nie same firmy, ale użytkownicy strukturyzują dane, żeby zyskać popularność. Stopniowo zdają sobie sprawę, że jeśli chcą opublikować popularną wiadomość w mediach społecznościowych, musi zawierać zdjęcia, tekst, czasem wideo. Dlatego po pewnym czasie wszystkie posty wyglądają tak samo. Prawie każdy dostaje dziś informacje o tym, jak popularne są jego posty: ile zdobyły lajków, ile osób je widziało. Facebook dostarcza te dane, bo chce, żeby zapłacić mu za dodatkową promocję. Ale ludzie też widzą, że jeśli użyją filtra, to zdobędą 5 lajków więcej – i zaczynają używać filtrów. To jest właśnie niebezpieczne. Także rankingi oglądalności funkcjonujące w mass mediach, np. w telewizji, stały się codziennością, każdy z nas przekształcił się w nadawcę kontrolującego skuteczność swoich przekazów. Sami siebie cenzurujemy, żeby zdobyć popularność.
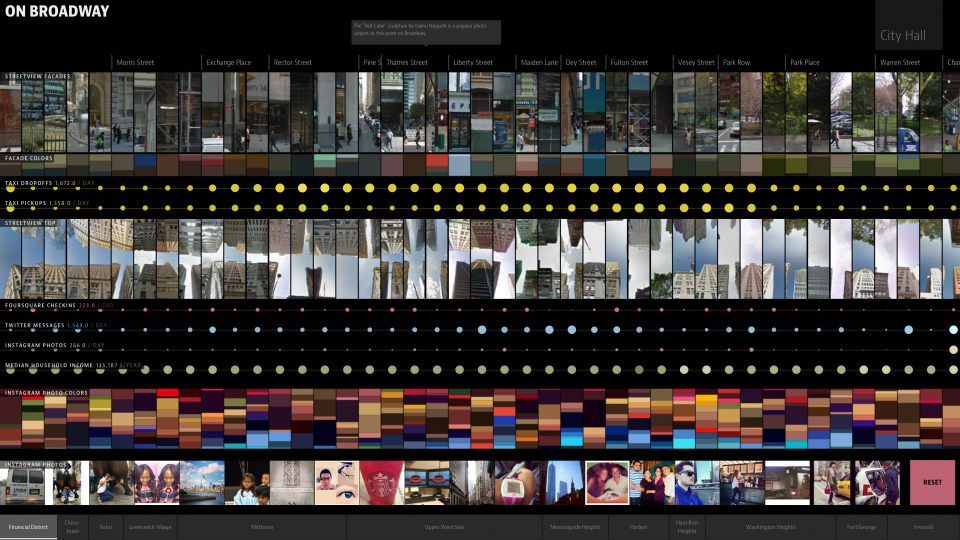
Wykorzystując dane z mediów społecznościowych, pokazujecie, jak wiele informacji można z nich wyciągnąć. Projekt „On Broadway” mógłby zostać wykorzystany przez firmy marketingowe do wyznaczenia najlepszych miejsc do umieszczania reklam. Ale przecież nie to jest waszym celem. Co właściwie chcecie osiągnąć, analizując te dane? Czy macie ambicje krytyczne?
Rzeczywiście, najwięcej takich badań prowadzą firmy zajmujące się badaniami trendów i marketingiem. Zresztą marketingowcy od dekad badają efektywność reklam. Nam chodzi o inne rzeczy. Po pierwsze, jako artysta wizualny chcę tworzyć dzieła sztuki, które reprezentowałyby społeczeństwo, wykorzystując elementy – komunikaty, zdjęcia – współtworzone przez tysiące, miliony ludzi. Takie impulsy były istotne w sztuce początku XX wieku: sceny przedstawiające ludzi w barze, na pikniku, na bulwarze. W pewnym sensie to już były media społecznościowe. Mój ulubiony przykład to filmy Dzigi Wiertowa z lat 20., rejestrujące życie na ulicach miast. Nikt nie policzył, ilu różnych ludzi pojawia się w filmie „Człowiek z kamerą filmową”, ale musiało ich być tysiące. Nasze badania różnią się od tego, co robił Wiertow, bo dziś to sami ludzie produkują obrazy. Być może pozwala to na nieco bardziej obiektywną reprezentację.
Po drugie, interesuje mnie demokratyzacja dostępu do danych. Interesuje mnie, jak możemy stworzyć takie interfejsy, aby ludzie, którzy nie znają się na informatyce, przeciętni obywatele, mogli pracować z dużymi zbiorami danych.
Wreszcie, po trzecie, jeśli ktoś chce zajmować się współczesną fotografią, to Instagram wydaje się właściwym miejscem, żeby to robić. Analiza tych danych pozwala rozpoznawać tendencje we współczesnej fotografii. Choć zawsze musimy pamiętać o zdaniu McLuhana, że „medium jest informacją” i odpowiadać sobie na pytanie, co właściwie analizujemy, kiedy zajmujemy się Instagramem: rzeczywistość społeczną? współczesną fotografię? a może fotografię instagramową? To zupełnie różne rzeczy.
 Lev Manovich na festiwalu NInA WERSJA BETA, fot. Bartek Syta
Lev Manovich na festiwalu NInA WERSJA BETA, fot. Bartek Syta
Wydaje się, że analityka kulturowa, którą uprawiasz, jest do pewnego stopnia deterministyczna. Pokazuje, że zachowania ludzi wcale nie są takie wyjątkowe, jak oni sami chcieliby myśleć, ale że są częścią trendów i konwencji. Czy pozostaje tu gdzieś miejsce na indywidualne różnice?
To najważniejsze pytanie, jakie możemy sobie dziś postawić. W jednym z ostatnich artykułów zajmowałem się tym, w jaki sposób rozwój nowoczesnych społeczeństw w XIX i XX wieku łączy się ze statystyką. Polega ona na eliminowaniu indywidualnych różnic i dąży do tego, żeby stworzyć obraz społeczeństwa za pomocą liczb. Kiedy wchodzę na Wikipedię, żeby dowiedzieć się czegoś o Warszawie, mogę przeczytać, jaka powierzchnia miasta przypada na jednego mieszkańca, jakie są tu średnie zarobki. Nic mi to jednak nie mówi o różnicach między ludźmi.
Pracuję – praktycznie i teoretycznie – nad tym, w jaki sposób możemy wykorzystać metody analizy i wizualizacji danych, aby połączyć je z analizą indywidualnych różnic. Czy możemy stworzyć naukę o tym, co konkretne. Nasze projekty zmierzają zasadniczo w tym właśnie kierunku. Tworzymy wizualizacje składające się z pojedynczych obrazów, na których można dostrzec nie tylko regularności, ale także pojedyncze zdjęcia. Stosunkowo łatwo osiągnąć taki efekt w przypadku zdjęć, znacznie trudniej to zrobić w przypadku innych rodzajów danych.
Dotyczy to zresztą nie tylko analityki kulturowej, ale generalnie tego, jak uprawiamy nauki społeczne czy naukę w ogóle. A nawet tego, jak urządzamy nasze społeczeństwa i jak dostosowujemy społeczne normy i prawa do jednostkowych różnic. Kiedy wypełnia się dziś formularz w urzędzie, zasadniczo wykorzystuje się XIX-wieczny pomysł statystyki, który zmusza cię do wybrania jednej spośród kilku kategorii. Kiedy jesteś pytany o płeć, to jest to kontynuacja myśli Arystotelesa, choć już sto lat temu Freud pokazywał, że płeć jest raczej wymiarem ciągłym. Facebook, który pozwala na wybór chyba 41 tożsamości genderowych, znacznie wyprzedza pod tym względem rządy.
Podczas Festiwalu NInA Wersja Beta prezentowałeś projekt „Selfiecity”. Interesujący był moment, kiedy po ustawieniu kilku filtrów, z całego zbioru pozostawało tylko jedno zdjęcie. Czy to odpowiednik takiej ciągłej tożsamości?
Dokładnie. Myślę, że powinienem opublikować kilka zrzutów ekranu z tego projektu, pokazując: tak możemy zdefiniować tę jednostkową tożsamość. Większość tych kategorii jest ciągła, a ta jedna osoba jest wyjątkowa, bo przechylenie jej głowy na zdjęciu wynosi tyle a tyle stopni.
A co masz na myśli, kiedy mówisz, że istnieje tylko oprogramowanie?
Powiedzmy, że masz na laptopie pliki PDF z artykułami. Żeby je obejrzeć albo komuś wysłać, musisz użyć oprogramowania. Możesz też stworzyć archiwum zawierające całe dziedzictwo wizualne Polski: filmy, programy telewizyjne, zdjęcia – ale aby je obejrzeć, musisz użyć jakiegoś programu. Zanim staliśmy się cyfrowi, mogliśmy polegać na naszych zmysłach. Nawet nowoczesne media, takie jak fotografia czy prasa drukarska, tworzyły reprezentacje, które mogliśmy obejrzeć albo przeczytać. Ale już w przypadku kasety wideo dostawałeś przedmiot i nie wiedziałeś, co jest w środku. Podobnie jest z twardym dyskiem: żeby uzyskać dostęp do medium, potrzebujesz oprogramowania, interfejsu.
Znaczna część mojej pracy dotyczy tego przesunięcia. W książce „Język nowych mediów” jeden z rozdziałów jest poświęcony interfejsowi jako formie kulturowej. Moja ostatnia książka mówi o tym, że w wielu przypadkach to, co możesz wydobyć z danej reprezentacji kulturowej, jest uzależnione od oprogramowania, którego użyjesz. Jeśli np. otworzę zdjęcie w domyślnej przeglądarce, mogę je obejrzeć, ewentualnie powiększyć. Ale jeśli użyję Photoshopa, będę mógł je zmienić, zwiększyć kontrast, dzięki czemu dostrzegę szczegóły, których wcześniej nie widziałem. Ostatecznie to, co możesz zobaczyć, zależy od oprogramowania.

Czy technologie najbliższej przyszłości: wirtualna rzeczywistość, internet rzeczy – wpłyną na twoje badania?
W tej chwili najbardziej interesują mnie obrazy tworzone przez ludzi. Ale ciekawią mnie też przestrzenie, na przykład właśnie to, w jaki sposób zmieniała się Warszawa. Media społecznościowe dają nam wiele informacji, ale są też w dużej mierze ograniczone: korzysta z nich pewien rodzaj ludzi, którzy publikują tam pewien rodzaj treści. Kiedy sprawdza się, skąd ludzie wysyłają posty, okazuje się, że poza dużymi miastami jest pustynia.
Ale jest lepsza technologia. Czytałem niedawno o firmie, który zdobyła 15 milionów dolarów na badania polegające na tym, że każdego dnia w kilkunastu miastach na świecie wysyłano do sklepów tysiące ankieterów, którzy robili zdjęcia etykiet z cenami. Tak zgromadzone dane posłużyły za podstawę do badań ekonomicznych. Gdybyśmy chcieli zbadać sieć księgarń w Warszawie i porównać ją z sieciami w tysiącu innych miast, najlepiej byłoby wysłać tam ludzi. To taka rozszerzona antropologia. Oczywiście możliwa dzięki aplikacjom pozwalającym na łatwe przesyłanie danych. Jednak to ludzie wciąż pozostają najlepszymi obserwatorami rzeczywistości.
Więc ostatecznie jesteś humanistą?
Oczywiście! Inaczej już dawno prowadziłbym własną firmę.
Tekst dostępny na licencji Creative Commons BY-NC-ND 3.0 PL (Uznanie autorstwa-Użycie niekomercyjne-Bez utworów zależnych).







































































































